
AI Papers
Anh-Kiet Duong, Petra Gomez-Krämer
Defactify4 @ AAAI 2025
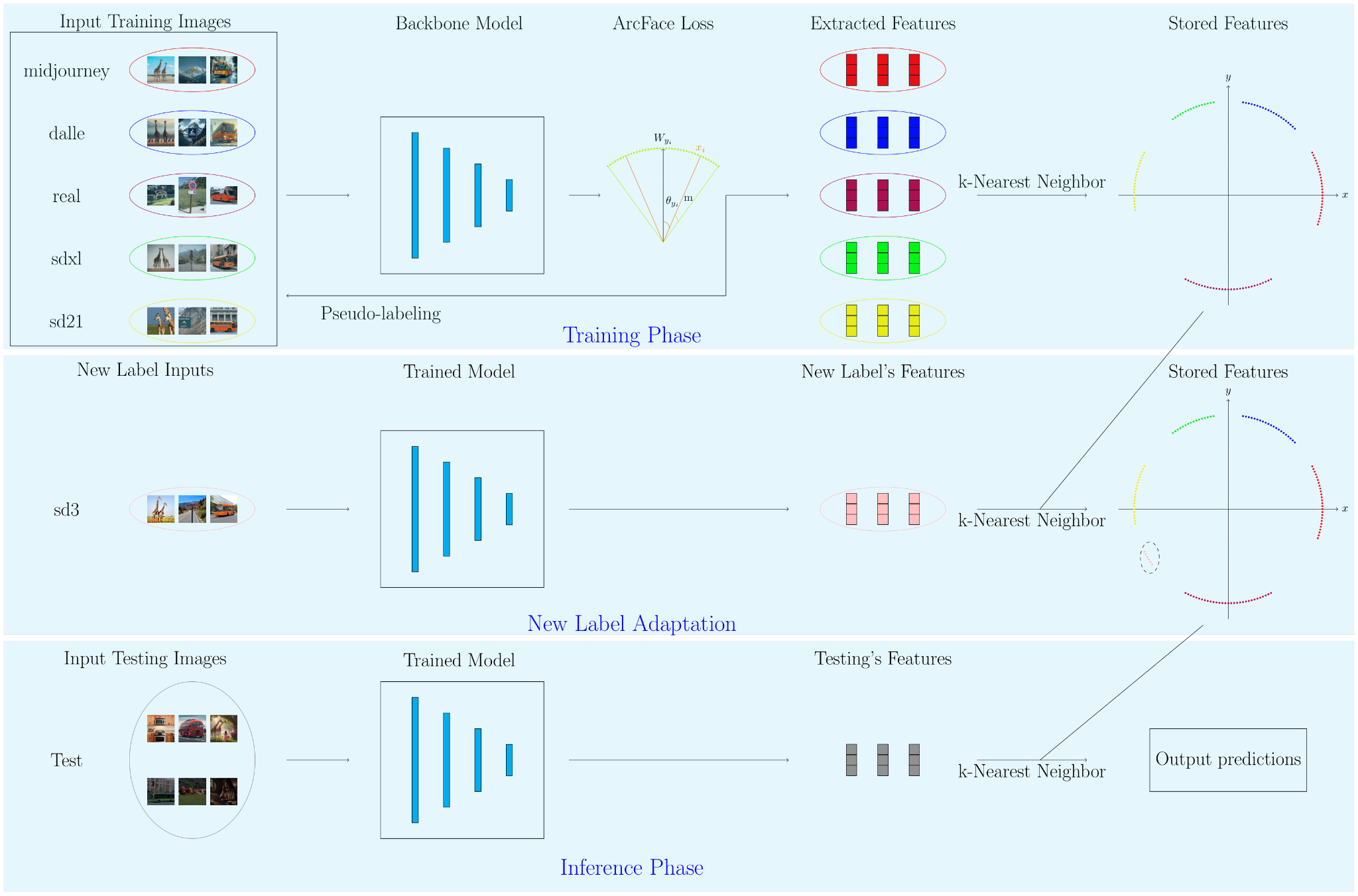
The rapid growth of generative AI technologies has heightened the importance of effectively distinguishing between human and AI-generated content, as well as classifying outputs from diverse generative models. This paper presents a scalable framework that integrates perceptual hashing, similarity measurement, and pseudo-labeling to address these challenges. Our method enables the incorporation of new generative models without retraining, ensuring adaptability and robustness in dynamic scenarios. Comprehensive evaluations on the Defactify4 dataset demonstrate competitive performance in text and image classification tasks, achieving high accuracy across both distinguishing human and AI-generated content and classifying among generative methods. These results highlight the framework’s potential for real-world applications as generative AI continues to evolve. Source codes are publicly available at https://github.com/ffyyytt/defactify4.

Anh-Kiet Duong, Petra Gomez-Krämer
WACV 2025
This paper presents a novel approach for hazard analysis in dashcam footage, addressing the detection of driver reactions to hazards, the identification of hazardous objects, and the generation of descriptive captions. We first introduce a method for detecting driver reactions through speed and sound anomaly detection, leveraging unsupervised learning techniques. For hazard detection, we employ a set of heuristic rules as weak classifiers, which are combined using an ensemble method. This ensemble approach is further refined with differential privacy to mitigate overconfidence, ensuring robustness despite the lack of labeled data. Lastly, we use state-of-the-art vision-language models for hazard captioning, generating descriptive labels for the detected hazards. Our method achieved the highest scores in the Challenge on Out-of-Label in Autonomous Driving, demonstrating its effectiveness across all three tasks. Source codes are publicly available at https://github.com/ffyyytt/COOOL_2025.
Anh-Kiet Duong, Petra Gomez-Krämer
27th International Conference on Pattern Recognition (ICPR) 2024
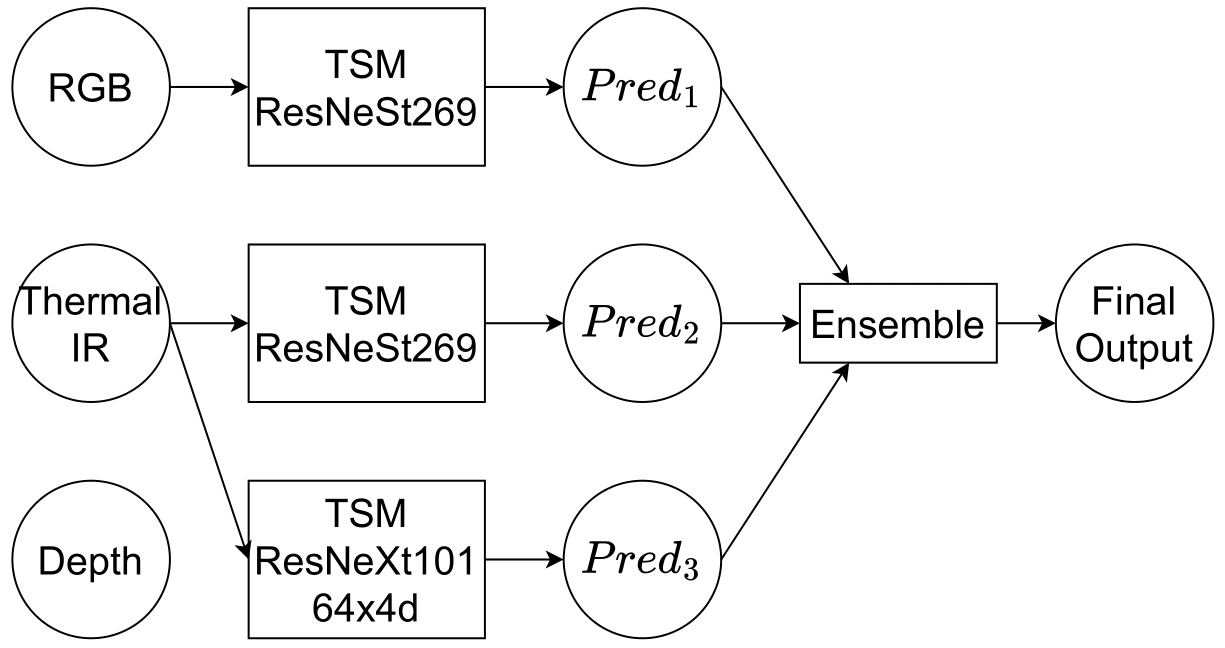
This paper presents the first-rank solution for the Multi-Modal Action Recognition Challenge, part of the Multi-Modal Visual Pattern Recognition Workshop at the \acl{ICPR} 2024. The competition aimed to recognize human actions using a diverse dataset of 20 action classes, collected from multi-modal sources. The proposed approach is built upon the \acl{TSM}, a technique aimed at efficiently capturing temporal dynamics in video data, incorporating multiple data input types. Our strategy included transfer learning to leverage pre-trained models, followed by meticulous fine-tuning on the challenge's specific dataset to optimize performance for the 20 action classes. We carefully selected a backbone network to balance computational efficiency and recognition accuracy and further refined the model using an ensemble technique that integrates outputs from different modalities. This ensemble approach proved crucial in boosting the overall performance. Our solution achieved a perfect top-1 accuracy on the test set, demonstrating the effectiveness of the proposed approach in recognizing human actions across 20 classes. Our code is available online https://github.com/ffyyytt/TSM-MMVPR.
Anh-Kiet Duong
Master thesis
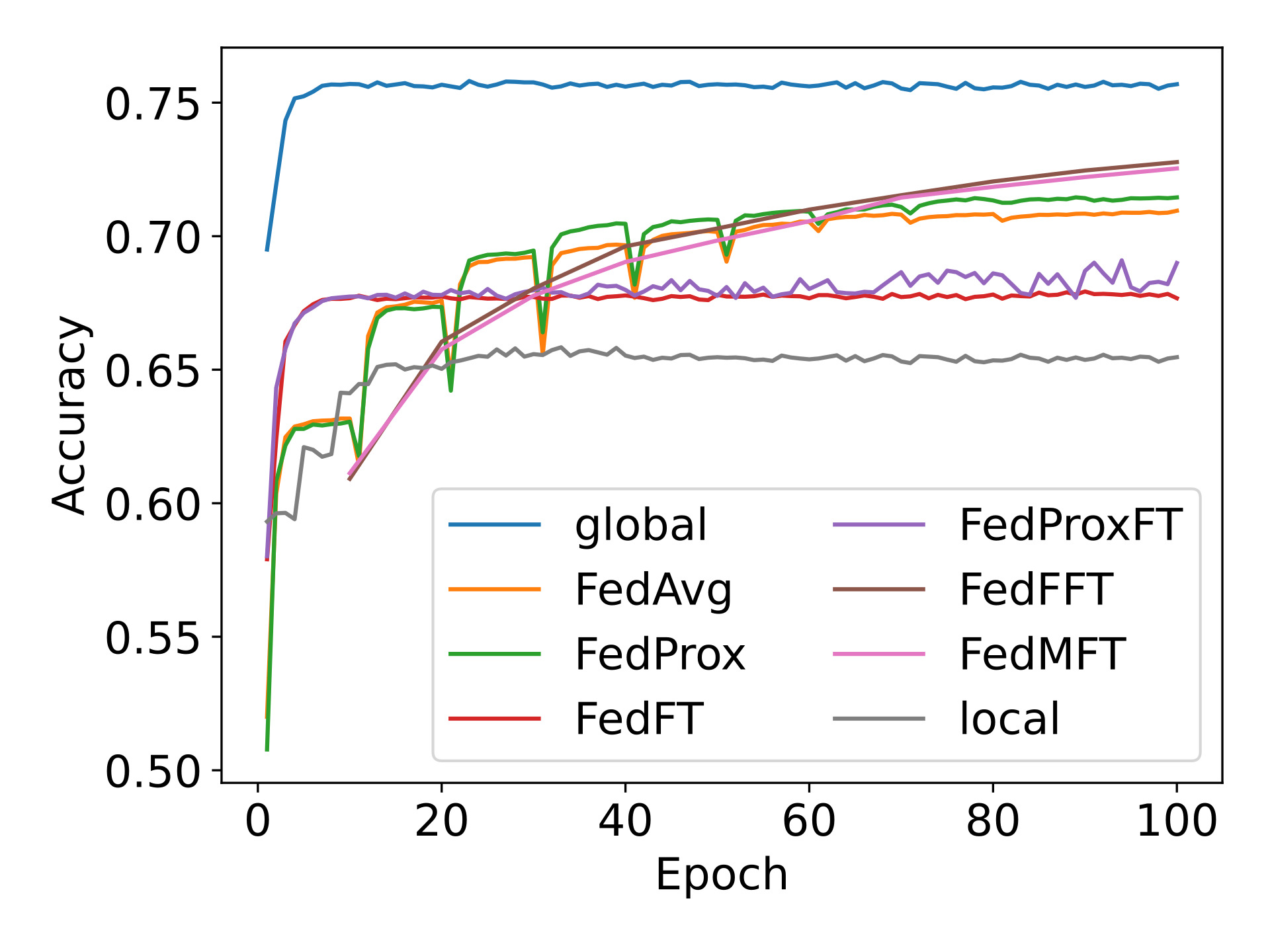
As Artificial Intelligence (AI) is advancing quickly, the research area of privacy and data security in Machine Learning (ML) is becoming very important. This is especially true when applying ML to distributed systems where data sharing happens often. In this thesis, we study the possibility of using Federated Learning (FL) to improve privacy by avoiding the need to share raw data between nodes. Also, we propose several FL methods that cut down on data transmission by using features rather than full models, which not only eases network congestion but also boosts security.
In terms of Machine Learning, we propose four FL algorithms and compare their performance with existing FL algorithms such as FedAvg and FedProx. We also demonstrate the practical application of the proposed method in a real-world scenario of ship detection, showing how FL can be effectively used to protect sensitive information while maintaining high performance.
In terms of Information Security, this work has a meaningful impact by addressing issues related to data sharing, inference attacks, and the amount of data transmitted over networks. Specifically, our feature-based data transfer method reduces network traffic while simultaneously improving security. We also investigate the impact of Membership Inference Attack (MIA) on traditional ML and FL methods to evaluate and compare those methods through privacy measures. These contributions significantly improve the ability of FL to address privacy and security issues in ML systems.
Anh-Kiet Duong, Hoàng-Ân Lê, Minh-Tan Pham
IEEE International Geoscience and Remote Sensing Symposium 2024 (IGARSS 2024)
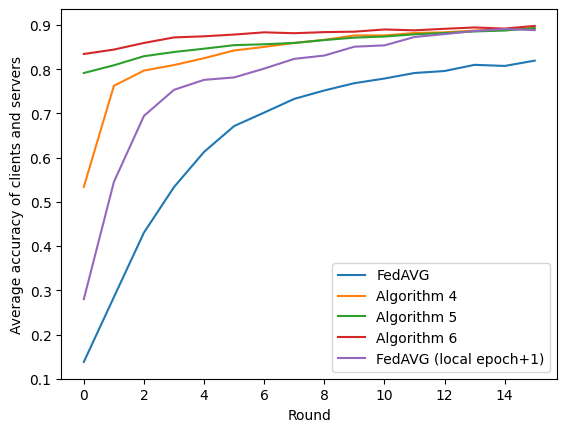
In the realm of Federated Learning (FL) applied to remote sensing image classification, this study introduces and assesses several innovative communication strategies. Our exploration includes feature-centric communication, pseudo-weight amalgamation, and a combined method utilizing both weights and features. Experiments conducted on two public scene classification datasets unveil the effectiveness of these strategies, showcasing accelerated convergence, heightened privacy, and reduced network information exchange. This research provides valuable insights into the implications of feature-centric communication in FL, offering potential applications tailored for remote sensing scenarios.
Mohammud Shaad Ally Toofanee, Mohamed Hamroun, Sabeena Dowlut, Karim Tamine, Vincent Petit, Anh Kiet Duong, Damien Sauveron
Applied Sciences 13.23 (2023)
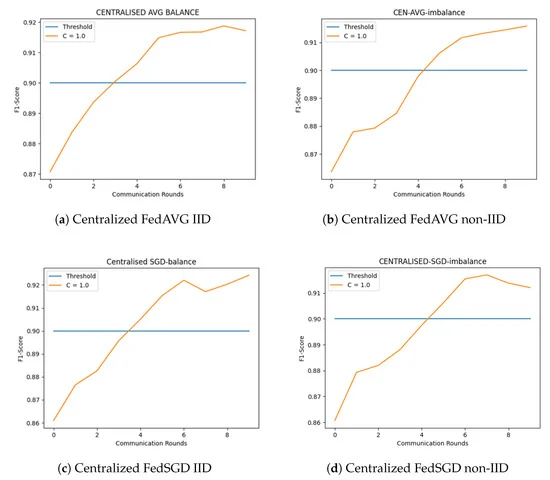
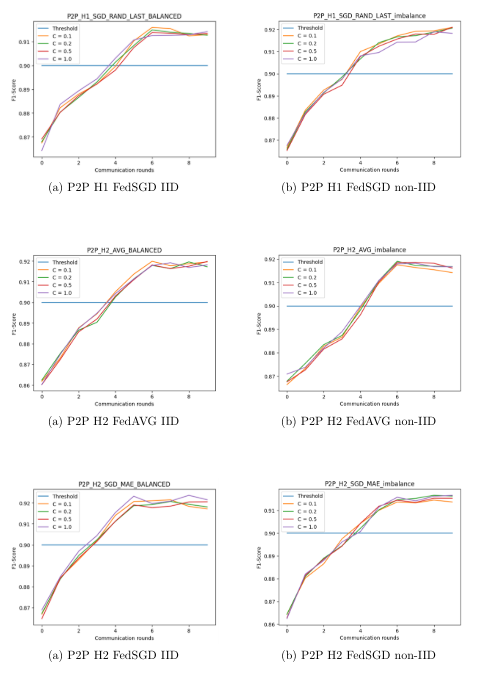
It is a known fact that AI models need massive amounts of data for training. In the medical field, the data are not necessarily available at a single site but are distributed over several sites. In the field of medical data sharing, particularly among healthcare institutions, the need to maintain the confidentiality of sensitive information often restricts the comprehensive utilization of real-world data in machine learning. To address this challenge, our study experiments with an innovative approach using federated learning to enable collaborative model training without compromising data confidentiality and privacy. We present an adaptation of the federated averaging algorithm, a predominant centralized learning algorithm, to a peer-to-peer federated learning environment. This adaptation led to the development of two extended algorithms: Federated Averaging Peer-to-Peer and Federated Stochastic Gradient Descent Peer-to-Peer. These algorithms were applied to train deep neural network models for the detection and monitoring of diabetic foot ulcers, a critical health condition among diabetic patients. This study compares the performance of Federated Averaging Peer-to-Peer and Federated Stochastic Gradient Descent Peer-to-Peer with their centralized counterparts in terms of model convergence and communication costs. Additionally, we explore enhancements to these algorithms using targeted heuristics based on client identities and f1-scores for each class. The results indicate that models utilizing peer-to-peer federated averaging achieve a level of convergence that is comparable to that of models trained via conventional centralized federated learning approaches. This represents a notable progression in the field of ensuring the confidentiality and privacy of medical data for training machine learning models.
Mohammud Shaad Ally Toofanee, Mohamed Hamroun, Sabeena Dowlut, Karim Tamine, Vincent Petit, Anh Kiet Duong, Damien Sauveron
Applied Sciences 13.18 (2023)
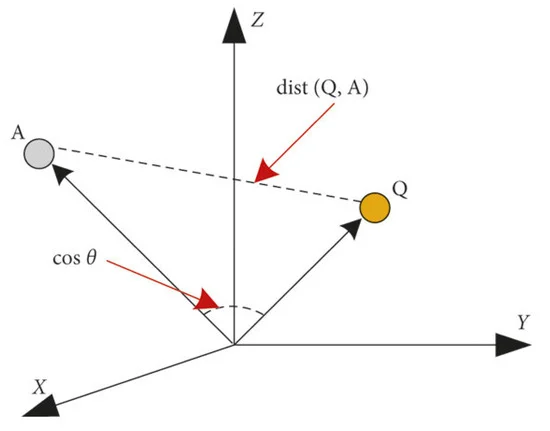
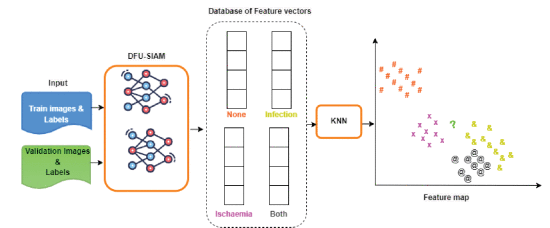
Diabetes affects roughly 537 million people, and is predicted to reach 783 million by 2045. Diabetes Foot Ulcer (DFU) is a major complication associated with diabetes and can lead to lower limb amputation. The rapid evolution of diabetic foot ulcers (DFUs) necessitates immediate intervention to prevent the severe consequences of amputation and related complications. Continuous and meticulous patient monitoring for individuals with diabetic foot ulcers (DFU) is crucial and is currently carried out by medical practitioners on a daily basis. This research article introduces DFU-Helper, a novel framework that employs a Siamese Neural Network (SNN) for accurate and objective assessment of the progression of diabetic foot ulcers (DFUs) over time. DFU-Helper provides healthcare professionals with a comprehensive visual and numerical representation in terms of the similarity distance of the disease, considering five distinct disease conditions: none, infection, ischemia, both (presence of ischemia and infection), and healthy. The SNN achieves the best Macro F1-score of 0.6455 on the test dataset when applying pseudo-labeling with a pseudo-threshold set to 0.9. The SNN is used in the process of creating anchors for each class using feature vectors. When a patient initially consults a healthcare professional, an image is transmitted to the model, which computes the distances from each class anchor point. It generates a comprehensive table with corresponding figures and a visually intuitive radar chart. In subsequent visits, another image is captured and fed into the model alongside the initial image. DFU-Helper then plots both images and presents the distances from the class anchor points. Our proposed system represents a significant advancement in the application of deep learning for the longitudinal assessment of DFU. To the best of our knowledge, no existing tool harnesses deep learning for DFU follow-up in a comparable manner.
Mohammud Shaad Ally Toofanee, Mohamed Hamroun, Sabeena Dowlut, Karim Tamine, Vincent Petit, Anh Kiet Duong, Damien Sauveron
IEEE Access (2023)
It is a known fact that AI models need massive amounts of data for training. In the medical field, the data are not necessarily available at a single site but are distributed over several sites. In the field of medical data sharing, particularly among healthcare institutions, the need to maintain the confidentiality of sensitive information often restricts the comprehensive utilization of real-world data in machine learning. To address this challenge, our study experiments with an innovative approach using federated learning to enable collaborative model training without compromising data confidentiality and privacy. We present an adaptation of the federated averaging algorithm, a predominant centralized learning algorithm, to a peer-to-peer federated learning environment. This adaptation led to the development of two extended algorithms: Federated Averaging Peer-to-Peer and Federated Stochastic Gradient Descent Peer-to-Peer. These algorithms were applied to train deep neural network models for the detection and monitoring of diabetic foot ulcers, a critical health condition among diabetic patients. This study compares the performance of Federated Averaging Peer-to-Peer and Federated Stochastic Gradient Descent Peer-to-Peer with their centralized counterparts in terms of model convergence and communication costs. Additionally, we explore enhancements to these algorithms using targeted heuristics based on client identities and f1-scores for each class. The results indicate that models utilizing peer-to-peer federated averaging achieve a level of convergence that is comparable to that of models trained via conventional centralized federated learning approaches. This represents a notable progression in the field of ensuring the confidentiality and privacy of medical data for training machine learning models.
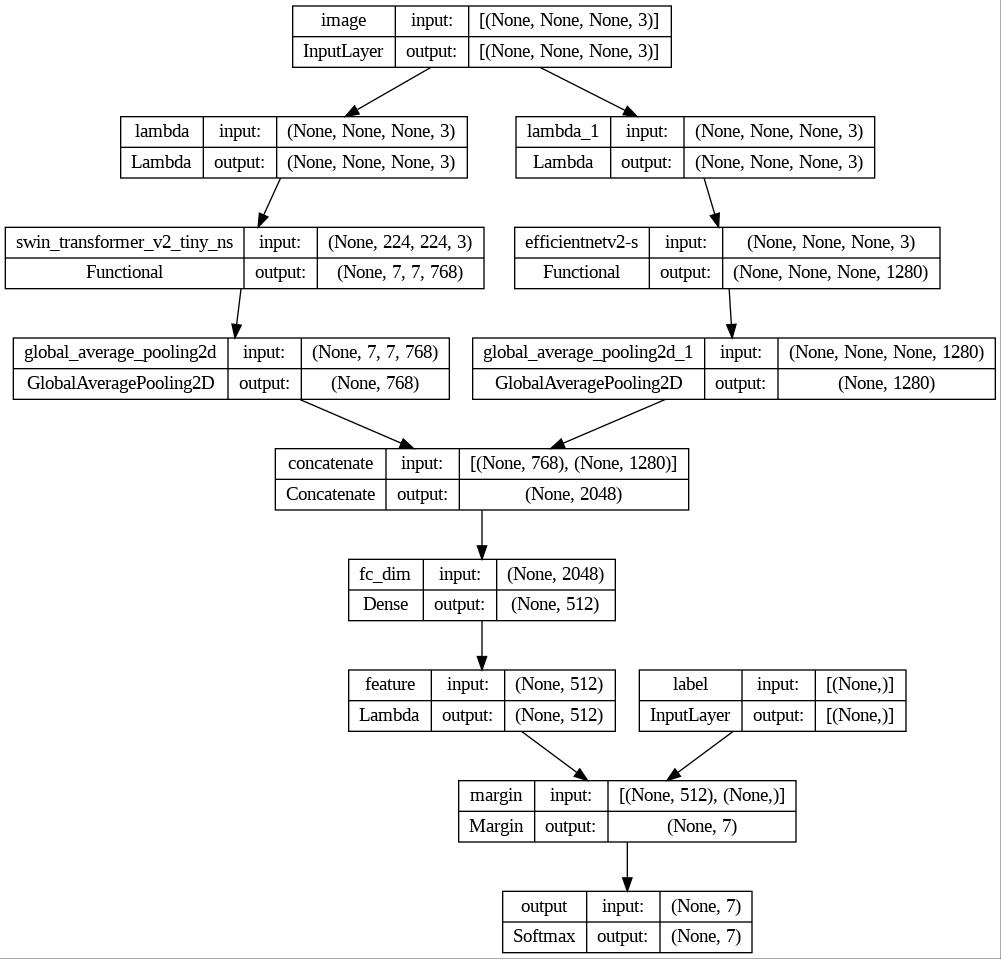
Enhancing Precision Agriculture: Deep Learning for Winter Crop Nutrient Defi-ciency Classification
This report outlines our approach and findings in the ”CVPPA@ICCV’23: Image Classification of Nutrient Deficiencies in Winter Wheat and Winter Rye” competition. We applied deep learning techniques to identify nutrient deficiencies in winter crops using the DND-Diko-WWWR dataset. Our model leveraged similarity learning, concatenation of two models, and pseudo-labeling for improved accuracy, showcasing the potential of computer vision in precision agriculture.
Federated Learning FL is a revolutionary approach to machine learning that addresses the challenges of data privacy and security. Traditional machine learning models rely on centralizing data from multiple sources, which can raise concerns about data privacy, especially when dealing with sensitive information. In contrast, FL allows for distributed learning across devices or servers, ensuring that data remains decentralized and secure.
By keeping data local, FL offers several key benefits in terms of data security. Firstly, it eliminates the need to transfer sensitive data over networks, reducing the exposure to potential security threats. This is particularly important in industries such as healthcare, finance, and telecommunications, where data confidentiality is paramount. Secondly, FL employs advanced encryption techniques to protect data during transmission and ensure that only encrypted model updates are shared, further enhancing the security of the learning process.


REMOVE NON-LANDMARK TO IMPROVE LANDMARK RECOGNITION
Landmark recognition can help people get more information about a place in a photo, or the system can better automatically align photos to their collection. The Google Landmarks Dataset v2 (GLDv2) [1] contains a more than 81,000 classes and the number of training examples per class may not be large is a big challenge for researchers to achieve high accuracy and stability. We propose a solution using the VGG16 model trained on the Places365 dataset and adding Haar-like features to detect and remove non-landmark images and increase efficiency for recognition. We have experimented on the model Deep Local and Global (DELG) [2] model. It helps improve the DELG model from 0.4341 to 0.4661 points Global Average Precision (GAP) on the GLDv2 dataset. With this result [3], we won a bronze prize in the Google Landmark Recognition 2020 competition.
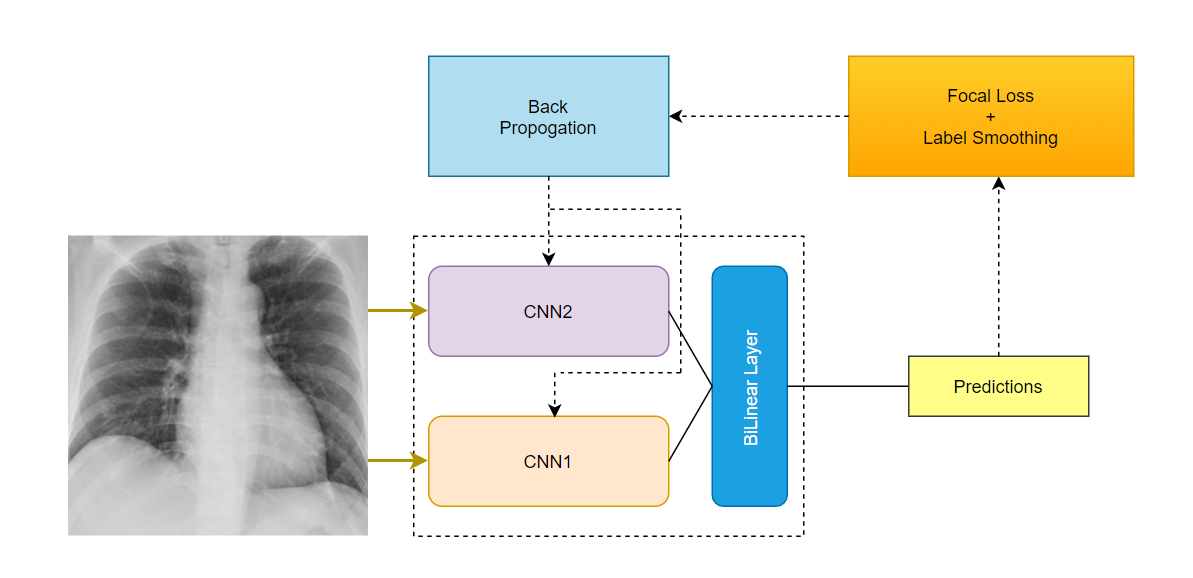
BiLinear CNNs Model and Test Time Augmentation for Screening Viral and COVID-19 Pneumonia
This year, COVID-19, a novel coronavirus has made a worldwide crisis. Several researchers have tried to create machine learning models to diagnose infections via their chest x-ray image. We noticed that some datasets are out of balance because of the bones, characters,... in the image. We present an image preprocessing to rebalance the dataset, test time augmentation to perform random modifications to the test images. And apply bilinear CNNs to the problem of screening Viral and COVID-19 pneumonia because different baseline architecture give different failure results. Our proposed can improve accuracy up to 1.4% compared to state-of-the-art on the dataset given by researchers Muhammad E. H. Chowdhury, Tawsifur Rahman, and their colleagues on the paper “Can AI help in screening Viral and COVID-19 pneumonia?”-IEEE Access. Through this paper, we hope to be able to help in diagnosing infections of COVID-19 and especially in the application of machine learning to this problem.

Large Margin Cotangent Loss for Deep Similarity Learning
Deep Convolutional Neural Networks (DCNN) models have become popular in feature extraction tasks. One of the best approaches to effectively classify the features is to utilize the loss function. Softmax loss is one of the losses initiated from One-Shot Learning method; however, using Softmax loss is considered impractical for real-world tasks since the number of labels can change frequently and require re-train when new labels emerge. In contrast, many types of loss function from Similarity Learning method such as Intra loss, Inter loss, Triplet loss, and Margin loss can tackle those drawbacks. Among them, the Margin-Loss-based losses have recently claimed to be the most effective strategies; such as CosFace, by adding a fixed parameter as a cosine margin to eliminate the dependence of the normal distribution to the cosine of weights and feature vectors; as well as ArcFace, by adding addictive angular penalty margins in the cosine function to simultaneously enhance class compactness and class differentiation. However, we evaluated that cosine functions used from these strategies do not fully represent the angle when they get smaller due to the limitation on the range of values. We propose Large Margin Cotangent Loss (LMCot), which uses cotangent function instead of cosine function since cotangent perform better by the unlimited on the range of values. As a result, our proposed method has great potential to improve performance on verification and identification tasks. Furthermore, we also experimented on various datasets from accredited competitions, the results of LMCot advanced the state-of-the-art in some measurements.
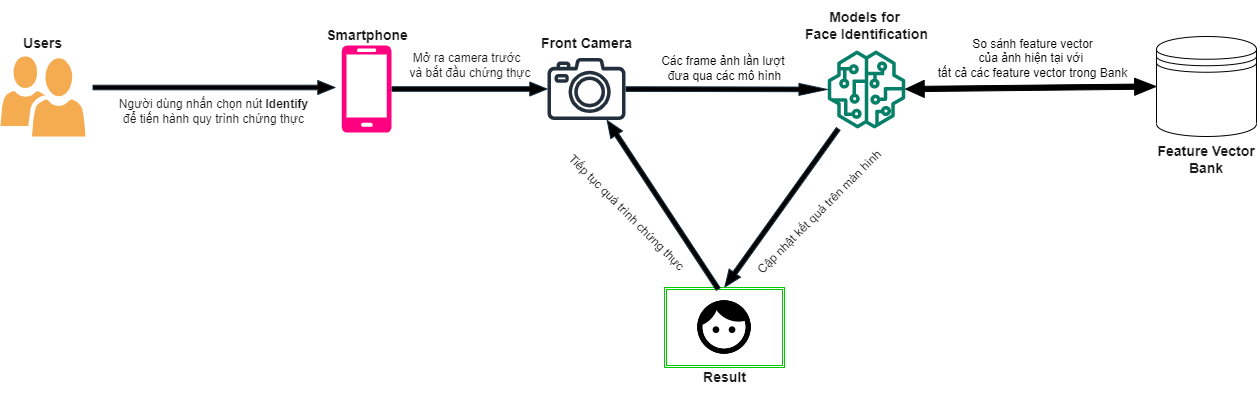
Enhanced Face Authentication With Separate Loss Functions
The overall objective of the main project is to propose and develop a system of facial authentication in unlocking phones or applications in phones using facial recognition. The system will include four separate architectures: face detection, face recognition, face spoofing, and classification of closed eyes. In which, we consider the problem of face recognition to be the most important, determining the true identity of the person standing in front of the screen with absolute accuracy is what facial recognition systems need to achieve. Along with the development of the face recognition problem, the problem of the anti-fake face is also gradually becoming popular and equally important. Our goal is to propose and develop two loss functions: LMCot and Double Loss. Then apply them to the face authentication process.
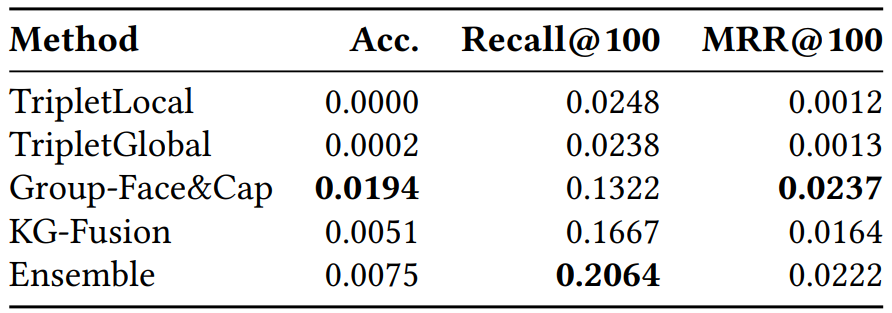
HCMUS at MediaEval 2020: Image-Text Fusion for Automatic News-Images Re-Matching
Matching text and images based on their semantics has an important role in cross-media retrieval. Especially, in terms of news, text and images connection is highly ambiguous. In the context of MediaEval 2020 Challenge, we propose three multi-modal methods for mapping text and images of news articles to the shared space in order to perform efficient cross-retrieval. Our methods show systemic improvement and validate our hypotheses, while the best-performed method reaches a recall@ 100 score of 0.2064.